
Stop manually defining your evaluation criteria and rubrics
A look at AdaRubric: automatically generating task adaptive rubrics for LLM agent evaluation

As we move from LLMs as chatbots to agents that take actions on our behalf, navigating complex, multi-step environments, we’ve hit a fundamental “evaluation wall.” We are asking agents to perform surgical-grade tasks (like debugging kernel code or navigating financial APIs), but we’re still grading them with blunt instruments (like LLM-judges for groundedness, factuality etc). We spend weeks of development time identifying the facets of quality we care about, the scoring rubric, and many hours of debate go into the exact definition of task success.
I read a recent paper “AdaRubric: Task-Adaptive Rubrics for LLM Agent Evaluation” (arXiv:2603.21362) which offers a solution: generating task evaluation criteria and rubrics on the fly, making them very specific to the task itself.

Contextualized Supervision
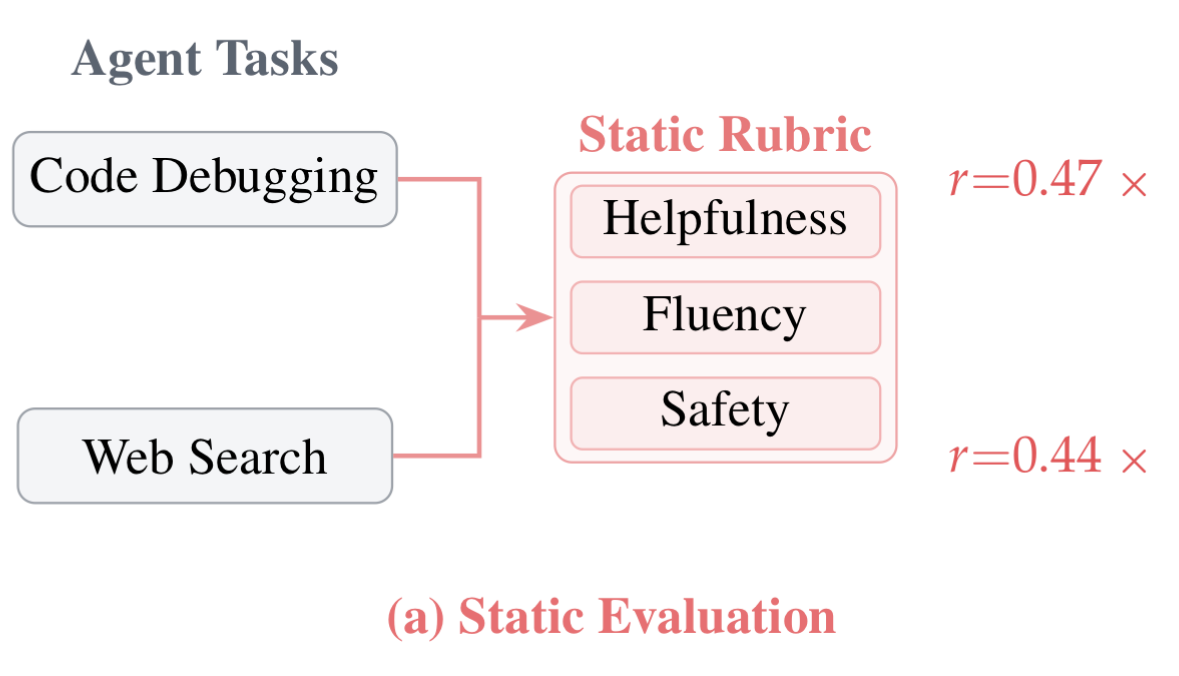
The central premise of AdaRubric is that evaluation is conditional on the task. For example, a code debugging agent and a web navigation agent are not optimizing for the same objective. Task success and evaluation criteria would naturally be different for these two agents. But frequently, we measure quality across a variety of tasks with the same evaluation rubrics. Using a “one-size-fits-all” rubric leads to quality masking, where an agent’s success in one area e.g. grammar or fluency hides a catastrophic failure e.g. logic or safety because a single score can’t provide enough information to distinguish between failure modes. Most LLM evaluation today ends up being structurally misaligned with what agents actually do.
AdaRubric makes a simple claim:
Evaluation dimensions should be a function of the task - not fixed properties of the evaluator.
Instead of scoring everything on generic axes like “helpfulness” or “fluency”, it generates task-specific rubrics on the fly, evaluates trajectories step-by-step across those dimensions, and uses that signal to train better agents.
The Shift in Trajectory
If you’ve worked on LLM evaluation (especially for agents), you’ve likely run into this:
Deterministic Metrics (BLEU/ROUGE) - Fails to capture semantic intent, not very useful for agents
LLM-as-a-Judge - Great for chatbots, but overly generic and chat-centric
Human evals - Expensive and slow to scale
The core issue is that we evaluate everything with the same rubric, irrespective of task context. AdaRubric moves toward a Structured Supervision approach. The model first designs the examination (the rubric) based on the specific constraints of the task, then uses that tailored rubric to score the trajectory.
Methodology: Deconstructing the Pipeline
AdaRubric operates as a two-step inference problem: first, define the rubric, then apply it with granularity.
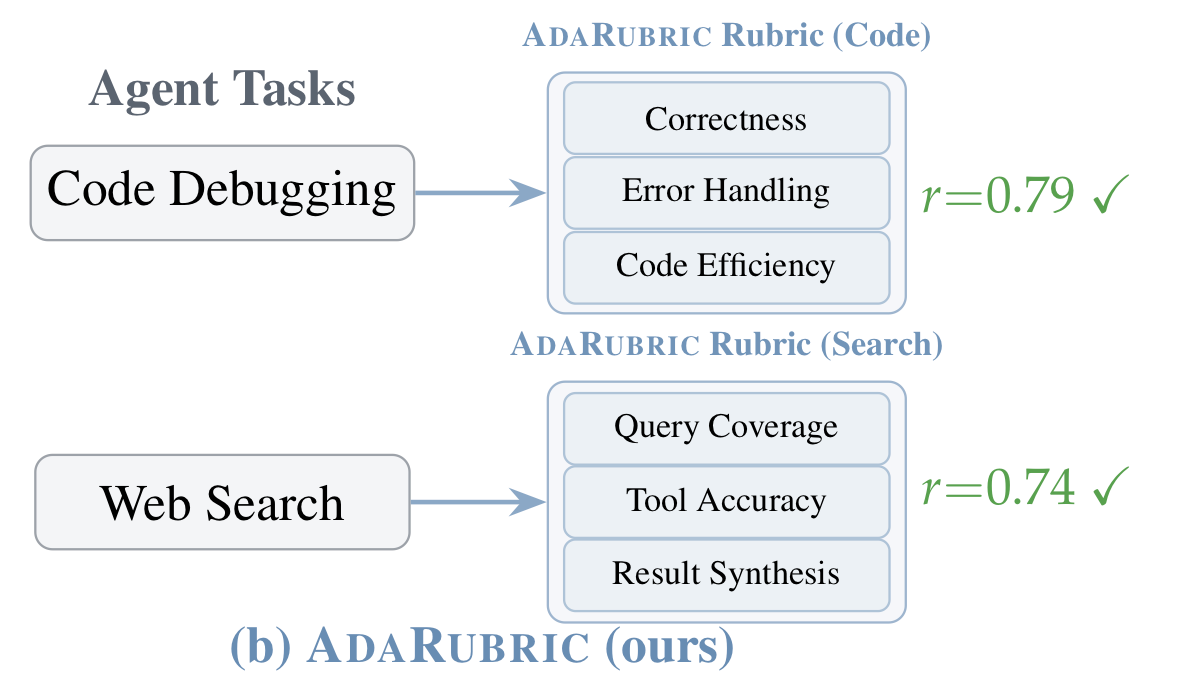
1. Task-Adaptive Rubric Generation
Given a task description T, the system induces a rubric
d_j: The specific dimension (e.g., API Correctness for tools, Constraint Satisfaction for travel booking).
w_j: The importance weight.
\Gamma_j: Calibrated scoring criteria (Likert-5) with behavioral anchors.
For example, a code debugging task has quality dimensions generated for correctness, error handling and efficiency whereas a web navigation task would have goal alignment, tool accuracy and results synthesis generated as rubrics.
2. Multi-Dimensional Dense Rewards
Instead of scoring a trajectory once at the end, AdaRubric evaluates each step k across each dimension j. If an agent performs 50 actions and the environment only returns a Score: 0 at the end, the model doesn’t know which specific API call or navigation step caused the failure. Because AdaRubric evaluates the entire trajectory, a score is assigned for each action. This solves the credit assignment problem.
This turns evaluation into a dense reward signal, which aligns naturally with RLHF and DPO pipelines. By weighting later steps more heavily (time-weighting), the model learns that terminal success is the ultimate goal, but step-level precision is the path to get there.
3. The Dimension-Aware Filter
I really like this paper’s practical idea of implementing a dimension-aware filter. DAF enforces a “no-hiding” rule: a trajectory cannot offset a failure in a critical dimension (like Security) with a high score in a secondary one (like Tone). It uses Krippendorff’s Alpha (>0.8) to ensure inter-rater reliability, filtering out noisy signals before they reach the training loop.
From Measurement to Supervision
By producing cleaner preference pairs, AdaRubric directly improves downstream performance:
Human Correlation: Achieved r ~ 0.79 (vs. ~ 0.46 for static baselines).
Training Gains: Agents trained via DPO using AdaRubric feedback saw a +6.8–8.5% increase in success rates on WebArena.
Zero-Shot Transfer: The system improved performance on SWE-bench code repair without any manual rubric engineering.
Where the Research Stops Short
While AdaRubric removes the need for manually defining rubrics, there are still several technical challenges:
The Recursive Fallacy: We rely on a “Meta-Evaluator” (e.g., GPT-4o) to grade a weaker model. We eventually hit a ceiling: How do we generate adaptive rubrics for models that are already at the frontier? There is no explicit grounding to environment rewards i.e. the rubric is derived from text, not from the “ground truth” of a successful API return.
The Orthogonality Assumption: The framework assumes dimensions are independent. In reality, Correctness and Efficiency are coupled. Redundant dimensions can artificially inflate reward signals.
Computational Overhead: The pipeline requires rubric generation, step-level scoring, and confidence estimation. For a training set of 50k trajectories, the inference cost of the evaluation could feasibly exceed the cost of the actual agent development, and that cost scales poorly with the number of steps in the trajectory.
Evaluation through critics
The deeper implication of AdaRubric is that we can move away from “searching for the right metric” and toward “engineering the right critic.”
If you’re building agentic systems today, the takeaway is clear: Stop engineering your quality criteria and rubrics manually. Once you decompose task success into interpretable, task-conditioned dimensions, you gain the ability to debug, align, and scale with a precision that generic judges simply cannot match.
What stood out most to me is that this tackles one of the most time-consuming parts of evaluation: defining quality dimensions and agreeing on a scoring rubric. In practice, this work spans multiple XFN teams - product, engineering, design - and often turns into long debates about what something like “text accuracy” even means in a given GenAI product context. AdaRubric operationalizes that work end to end and meaningfully reduces the overhead by generating task-aligned rubrics automatically - and importantly, shows that this approach actually works in practice.